Overview of GoldenGate Components Continued
5) Extract Files :-
- When you want to do processing a one-time run,such as an initial load or a batch run that synchronizes transactional changes,GoldenGate stores the extracted changes in an extract file instead of a trail.
- The extract file mostly is a single file but can be configured to split into multiple files in anticipation of limitations on the size of a file that are imposed by the operating system. In this sense,it is similar to a trail,except that checkpoints are not recorded.
- The file or files are created automatically during the run.Versioning features that apply to trails also apply to extract files.
6) Checkpoints :-
- Checkpoints store the current read and write positions of a process to disk for recovery purposes.Checkpoints ensure that database changes marked for synchronization are extracted by Extract and replicated by Replicat to prevent redundant processing.
- They provide fault tolerance by preventing the loss of data when the system,the network,or a GoldenGate process need to be restarted.For advanced synchronization configurations, checkpoints enable multiple Extract or Replicat processes to read from the same set of trails.
- The read checkpoint of a process is always synchronized with the write checkpoint.Thus,if GoldenGate needs to re-read something that it already sent to the target system (for example,after a process failure) checkpoints enable accurate recovery to the point where a new transaction starts, and GoldenGate can resume processing.
- Checkpoints work with inter-process acknowledgments to prevent messages from being lost in the network.Extract creates checkpoints for its positions in the data source and in the trail. Replicat creates checkpoints for its position in the trail.
- A checkpoint system is used for Extract and Replicat processes that operate continuously,but it is not required for Extract and Replicat processes that run in batch mode. A batch process can be re-run from its start point, whereas continuous processing requires the support for planned or unplanned interruptions that is provided by checkpoints.
- Checkpoint information is maintained in checkpoint files within the dirchk sub-directory of the GoldenGate directory. Optionally,Replicat’s checkpoints can be maintained in a checkpoint table within the target database,in addition to a standard checkpoint file.
7) Manager :-
- Manager is the control process of GoldenGate. Manager must be running on each system in the GoldenGate configuration before Extract or Replicat can be started, and Manager must remain running while those processes are running so that resource management functions are performed.
Manager performs the following functions:
- Monitor and restart GoldenGate processes.
- Issue threshold reports, for example when throughput slows down or when synchronization latency increases.
- Maintain trail files and logs.
- Allocate data storage space.
- Report errors and events.
- Receive and route user requests from the user interface.
One Manager process can control many Extract or Replicat processes. On Windows systems, Manager can run as a service.
8) Collector :-
- Collector is a process that runs in the background on the target system. Collector receives extracted database changes that are sent across the TCP/IP network, and it writes them to a trail or extract file.
- Manager starts Collector automatically when a network connection is required. When Manager starts Collector, the process is known as a dynamic Collector, and GoldenGate users generally do not interact with it. However, you can run Collector manually. This is known as a static Collector.
- Not all GoldenGate configurations use a Collector process.When a dynamic Collector is used, it can receive information from only one Extract process,so there must be a dynamic Collector for each Extract that you use. When a static Collector is used, several Extract processes can share one Collector. However, a one-to-one ratio is optimal.
- The Collector process terminates when the associated Extract process terminates.By default, Extract initiates TCP/IP connections from the source system to Collector on the target, but GoldenGate can be configured so that Collector initiates connections from the target. Initiating connections from the target might be required if, for example, the target is in a trusted network zone, but the source is in a less trusted zone.
Tuesday, November 3, 2009
GoldeGate Architecture

Components of GoldenGate :-
1) Extract Process :-
- Extract process runs on Source system and is the Capturing mechanism of Goldengate.It captures all the changes that are made to the objects for which it is configured for synchronization.
- It sends only the data from commited transactions to the trail for propogation to the target system.
- When extract captures the commit record of a transaction,all the log records for that transaction are written to the trail as a sequentially organized transaction unit. This maintains both speed and data integrity.
- Multiple Extract processes can operate on different objects at the same time. For example,one process could continuously extract transactional data changes and stream them to a decision-support database, while another process performs batch extracts for periodic reporting.
Or, two Extract processes could extract and transmit in parallel to two Replicat processes (with two trails) to minimize target latency when the databases are large. To differentiate among different processes, we can assign each one a group name.
Extract can be configured in two ways :-
- Initial Loads :- For initial data loads, Extract extracts a current set of data directly from their source objects.
- Change Synchronization :- To keep source data synchronized with another set of data,Extract extracts transactional changes made to data (inserts, updates, and deletes) after the initial synchronization has taken place. DDL changes and sequences are also extracted, if supported for the type of database being used.
Extract obtains the data from a data source in one of the following ways :-
- Database Transaction Logs :- (such as the Oracle redo logs or SQL/MX audit trails) This method is known as log-based extraction. When Extract is installed as a log-based implementation, it can read the transaction logs directly.
- GoldenGate Vendor Access Module (VAM) :- VAM is a layer for communication that passes data changes and transaction metadata to the Extract process. The database vendor provides the components that extract the data changes and pass it to Extract.
2) Data Pump :-
- Data pump is a secondary Extract group within the source GoldenGate configuration.If a data pump is not used, Extract must send data to a remote trail on the target.
- If we are using a configuration that includes a data pump,the primary Extract group writes to a trail on the source system.The data pump reads this trail and sends the data through the network to a remote trail on the target.
- Data pump adds the flexibility of storage and help to eliminate the load on the primary Extract process from TCP/IP activity.
Like a primary Extract group, a data pump can be configured in two modes :-
- Online or Batch processing :- Can perform data filtering, mapping, and conversion.
- Pass-through mode :- Data is passively transferred as-it is, without any manipulation.It increases the throughput of the data pump as the functionality of that looks up object definitions is bypassed.
In most business cases, it is best practice to use a data pump.
Some reasons for using a data pump include the following :-
- Protection against network and target failures:- In a basic GoldenGate configuration,with only a trail on the target system,there is no place on the source system to store data that Extract process continuously extracts into memory. If becuase of any reason the network or the target system becomes unavailable, the primary Extract could run out of memory and abend.
However,with a trail and data pump on the source system,captured data can be moved to disk,preventing the abend.When connectivity is restored,the data pump extracts the data from the source trail and sends it to the target system(s).
- Several phases of data filtering or transformation :- When using complex filtering or data transformation configurations, you can configure a data pump to perform the first transformation either on the source system or on the target system,and then use another data pump or the Replicat group to perform the second transformation.
- Consolidating data from many sources to a central target :- When synchronizing multiple source databases with a central target database, you can store extracted data on each source system and use data pumps on each of those systems to send the data to a trail on the target system. Dividing the storage load between the source and target systems reduces the need for massive amounts of space on the target system to accommodate data arriving from multiple sources.
- Synchronizing one source with multiple targets :- When sending data to multiple target systems, you can configure data pumps on the source system for each target. If network connectivity to any of the targets fails, data can still be sent to the other targets.
3) Replicat Process :-
- Replicat process runs on the target system. Replicat reads extracted data changes and DDL changes (if supported) that are specified in the Replicat configuration, and then it replicates them to the target database.
Replicat process can be configured in one of the following ways:-
- Initial loads: For initial data loads, Replicat can apply data to target objects or route them to a high-speed bulk-load utility.
- Change synchronization: To maintain synchronization, Replicat applies extracted transactional changes to target objects using native database calls, statement caches,and local database access. Replicated DDL and sequences are also applied, if supported for the type of database that is being used. To maintain data integrity, Replicat applies the replicated changes in the same order as those changes were committed to the source database.
- You can use multiple Replicat processes with multiple Extract processes in parallel to increase throughput.Each set of processes can handle different objects.To differentiate among processes, you assign each one a group name.
- You can delay Replicat so that it waits for a specific amount of time before applying data to the target database.A delay may be useful for such purposes to prevent the propagation of bad SQL, to control data arrival across different time zones, and to allow time for other planned events to
occur.DEFERAPPLYINTERVAL parameter can be used for controlling length of the delay.
4) Trails :-
- Trail is a series of files to store the supported database changes temporarily on disk to support the continuous extraction and replication.
- It can exist on the source or target system, or on an intermediary system, depending on how you configure GoldenGate.
- On the local system it is known as an extract trail (or local trail). On a remote system it is known as a remote trail.
- By using a trail for storage, GoldenGate ensures data accuracy and fault tolerance.
- The use of a trail is that it allows extraction and replication activities to occur independently of each other.
- With these processes separated,you have more choices for how data is delivered. For example, instead of extracting and replicating changes continuously, you could extract changes continuously but store them in the trail for replication to the target later, whenever the target application needs them.
- Only one Extract process can write to a trail.
Processes that read the trail are :-
- Data-pump Extract: Extracts data from a local trail for further processing,and transfers it to the target system or to the next GoldenGate process downstream in the GoldenGate configuration.
- Replicat: Reads a trail to apply change data to the target database.
For information on other components please read another topic.
Monday, November 2, 2009
GoldenGate Supported Topologies

{kind=link}
1) Uni-Directional :- This topology can be used to create a reporting instance out of OLTP databases or to offload the reporting on OLTP or Production database.
2) Bi-Directional :- Can be used for Active-Active Instant failover.For example,If we want to apply patch on one database we can use another for our application like rolling upgrade in Oracle Real Application Clusters.
3) Peer-To-Peer :- Used in the case of High Availability and Load Balancing.High Availability mean if any of the database fails because of any reason(Hardware Failure,Disk Failure or Instance Failure) our application would not get affected becuase other two databases will be up and running.Other benefit is that load is also being shared between the databases equally.
4) Broadcast :- Used for Data Distribution.If we have Production database and we want to do different kind of things (reporting,testing and development)on the data being stored .Then we can distribute the data between same or different databases and can be used for different purposes mentioned above.
5) Consildation :- If want to create common datawarehouse by consolidating the data from the datamarts of various departments in the enterprise.
6) Cascading :- Can be used for Scalability and Database Tiering.If want the move the production database to testing database and then to move the results of testing into various other databases of other departments.We can use any of the above topologies in any manner to do cascading like in the diagram is Uni-directional and then Broadcasting is used.
GoldenGate Features and Capabilities
Oracle acquired GoldenGate on September 3,2009.
GoldenGate enables the exchange and manipulation of data at the transaction level among multiple, heterogeneous platforms across the enterprise.
GoldenGate Features and Capabilites :-
1) Filtering :- Gives the flexibility to select and replicate the desired amount of data from the source(s) that could be Database(s),Flat files,File systems,Datawarehouse,etc.
2) Transformation :- Gives the capability to move the data between two different kind of databases like between SQL Server and Oracle,IBM DB2 and Oracle by transformation.
3) Custom Processing :- Allows to perform complex mappings and to use Ibuild selective functions for processing.Gives the option for scheduling also.
4) Real-Time :- Log-based capture capability allows to move thousands of transactions per second with very low impact.
5) Heterogenous :- Allows to move changed data accross different databases and platforms.
6) Transactional :- Can work in transactional environments as well by maintaining the transactional integrity.
7) Performance :- More performance because of Log-based capture.
8) Extensibility and Flexibility :- Its open and modular architecture allows to extract and replicate selected data records, transactional changes, and changes to DDL across a variety of topologies.
9) Reliability :- It is resilient against failures and interruptions by maintaining checkpoints,trails and logs.
GoldenGate enables the exchange and manipulation of data at the transaction level among multiple, heterogeneous platforms across the enterprise.
GoldenGate Features and Capabilites :-
1) Filtering :- Gives the flexibility to select and replicate the desired amount of data from the source(s) that could be Database(s),Flat files,File systems,Datawarehouse,etc.
2) Transformation :- Gives the capability to move the data between two different kind of databases like between SQL Server and Oracle,IBM DB2 and Oracle by transformation.
3) Custom Processing :- Allows to perform complex mappings and to use Ibuild selective functions for processing.Gives the option for scheduling also.
4) Real-Time :- Log-based capture capability allows to move thousands of transactions per second with very low impact.
5) Heterogenous :- Allows to move changed data accross different databases and platforms.
6) Transactional :- Can work in transactional environments as well by maintaining the transactional integrity.
7) Performance :- More performance because of Log-based capture.
8) Extensibility and Flexibility :- Its open and modular architecture allows to extract and replicate selected data records, transactional changes, and changes to DDL across a variety of topologies.
9) Reliability :- It is resilient against failures and interruptions by maintaining checkpoints,trails and logs.
Wednesday, September 23, 2009
Advantages of Oracle Data Integrator (E-LT) over other ETL tools
1) Faster and simpler development and maintenance :- The declarative rules driven approach to ETL greatly reduces the learning curve of the product and increases developer productivity while facilitating ongoing maintenance. This approach separates the definition of the processes from their actual implementation, and separates the declarative rules (the “what”) from the data flows (the “how”).
2) Ensures Data Quality :- Faulty data is automatically detected and recycled before insertion into the target application with the help of data integrity rules and constraints defined both on the target application and in Oracle data Integrator.
3) Better Performance :- As ODI is an E-LT tool it takes the advantage of set based level data transformation execution.And traditional ETL tool they do row by row data transformations.
4) Simple and efficient architecture :- ETL hub server is not needed in this between source and the target server.It uses target server RDBMS engine to perform complex transformations, most of which happen in batch mode when the server is not busy processing end-user queries.
5) Platform Independence :- Oracle Data Integrator supports all platforms, hardware and OSswith the same software.
6) Data Connectivity :- Supports all RDBMSs including all leading Data Warehousing platforms such as Teradata, IBM DB2, Netezza, Oracle, Sybase IQ and numerous other technologies such as flat files, ERPs, LDAP, XML.
7) Cost-savings :- Elimination of the ETL hub server and ETL engine reduces both the initial hardware and software acquisition and maintenance costs.
2) Ensures Data Quality :- Faulty data is automatically detected and recycled before insertion into the target application with the help of data integrity rules and constraints defined both on the target application and in Oracle data Integrator.
3) Better Performance :- As ODI is an E-LT tool it takes the advantage of set based level data transformation execution.And traditional ETL tool they do row by row data transformations.
4) Simple and efficient architecture :- ETL hub server is not needed in this between source and the target server.It uses target server RDBMS engine to perform complex transformations, most of which happen in batch mode when the server is not busy processing end-user queries.
5) Platform Independence :- Oracle Data Integrator supports all platforms, hardware and OSswith the same software.
6) Data Connectivity :- Supports all RDBMSs including all leading Data Warehousing platforms such as Teradata, IBM DB2, Netezza, Oracle, Sybase IQ and numerous other technologies such as flat files, ERPs, LDAP, XML.
7) Cost-savings :- Elimination of the ETL hub server and ETL engine reduces both the initial hardware and software acquisition and maintenance costs.
Thursday, April 23, 2009
Installation and Configuration of ILM:-(Partitioning)
For Installing database,go to setup.exe and double click on it :-


Select the Advanced Installation type for Installation Method :-





Select the Database Configuration as General Purpose :- (Can select other options as well depending on the requirement)


 Keep the option Database Control for Database Management :-
Keep the option Database Control for Database Management :-





 Click on the Install option :-
Click on the Install option :-

Click on ok :-

Copy the information somewhere mentioned about Oracle Enterprise Manager and click on exit:-

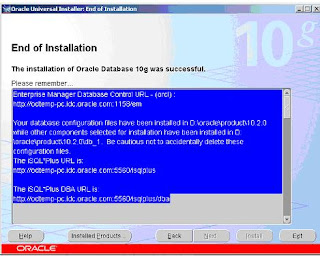
Automatically after exiting from the installation the Oracle Database Control will open :-
 Give the Username as SYS,Password as given at the time of Installation and Connect as SYSDBA :-
Give the Username as SYS,Password as given at the time of Installation and Connect as SYSDBA :-

After clicking on Login,Oracle Database 10g Licensing Information will come and we need to select the option I agree if we are licensed for Database Diagnostic,Tuning and Configuration Management Pack.
Now,we need to install HTTP Server as well for Installing Application Express which is used for ILM Console.HTTP Server download we can get from thee Companion CD of Oracle Database 10g.
Click on setup.exe :-

Select the option Oracle Database 10g Companion Products 10.2.0.1.0 because only HTTP Server is needed :-

Select the Path depending on the space in the drives but the HTTP Server home should be separate from Oracle Database Home :-

Select the Apache Standalone option and click on Next :-




Save the Information about the HTTP server :-








You can use the Windows Services utility, located either in the Windows Control Panel or from the Administrative Tools menu (under Start and then Programs), to shut down Oracle Database and ASM instances. Names of Oracle databases are preceded with OracleService. The Oracle ASM service is named OracleASMService+ASM. In addition, shut down the OracleCSService service, which ASM uses. Right-click the name of the service and from the menu, choose Stop.
3. Start the Oracle Database instance that contains the target database.
After backing up the system, you must start the Oracle instance that contains the target Oracle database. Do not start other processes such as the listener or Oracle HTTP Server. However, if you are performing a remote installation, make sure the database listener for the remote database has started. To start the database instance or listener, you can use the Windows Services utility.
To install Oracle Application Express release 3.0:
1. Download the file apex_3.0.zip from the Oracle Application Express download page. See:http://www.oracle.com/technology/products/database/application_express/download.html
2. Unzip apex_3.0.zip as follows, preserving directory names:
o UNIX and Linux: Unzip apex_3.0.zip
o Windows: Double click the file apex_3.0.zip in Windows Explorer
3. Change your working directory to apex.
Change the working directory where the apex folder exists and then connect to the database by SYS user :-


@apexins password tablespace_apex tablespace_files tablespace_temp images
Where:
o password is the password for the Oracle Application Express administrator account, the Application Express schema owner, and the Application Express files schema owner.
The Application Express schema owner is the user or schema into which Oracle Application Express database objects will be installed. The Application Express files schema owner is the user or schema where uploaded files are maintained in Oracle Application Express.
o tablespace_apex is the name of the tablespace for the Oracle Application Express application user.
o tablespace_files is the name of the tablespace for the Oracle Application Express files user.
o tablespace_temp is the name of the temporary tablespace.
o images is the virtual directory for Oracle Application Express images. To support future Oracle Application Express upgrades, define the virtual image directory as /i/.
The following examples demonstrate running apexins.sql and passing these arguments:

Copying the Images Directory in a New Installation :-
On Windows:
xcopy /E /I ORACLE_HOME\apex\images ORACLE_HTTPSERVER_HOME\Apache\images
Configuring Oracle HTTP Server 10g :-
Editing the dads.conf File :-
If this is a new installation of Application Express, you need to edit the dads.conf file. The dads.conf file contains the information about the DAD to access Oracle Application Express.
Use a text editor and open the dads.conf.
On Windows see: ORACLE_HTTPSERVER_HOME\Apache\modplsql\conf\dads.conf





· ORACLE_HTTPSERVER_HOME\opmn\bin\opmnctl stopproc ias-component=HTTP_Server
Go to link http://odtemp-pc.idc.oracle.com:7777/pls/apex/apex_admin to access application express console :-







Click on Run :-
Select the Advanced Installation type for Installation Method :-
Select Enterprise Edition for type of Installation :-
Keep the name of Oracle Home same but change the path of installation of oracle database according to the space in the drive :- (For example I have selected D: drive)
Select the configuration Option Create database :-
Select the Database Configuration as General Purpose :- (Can select other options as well depending on the requirement)
It will automatically take the Global Database Name as orcl and the Database Character Set also,we need not to change these two parameters :-
Check the option Create database with sample schemas :-
Keep the option Database Control for Database Management :- Select File System as Database Storage Option :- (We can select ASM also according to the environment)
We can select any of the options for Enabling and Disabling of Automated backups,but here in this case select the option Do not enable Automated Backups :-
We can specify different passwords for different accounts but here we are giving same password for all accounts :-
 Click on the Install option :-
Click on the Install option :-Click on ok :-
Copy the information somewhere mentioned about Oracle Enterprise Manager and click on exit:-
Automatically after exiting from the installation the Oracle Database Control will open :-
Give the Username as SYS,Password as given at the time of Installation and Connect as SYSDBA :-After clicking on Login,Oracle Database 10g Licensing Information will come and we need to select the option I agree if we are licensed for Database Diagnostic,Tuning and Configuration Management Pack.
Now,we need to install HTTP Server as well for Installing Application Express which is used for ILM Console.HTTP Server download we can get from thee Companion CD of Oracle Database 10g.
Click on setup.exe :-
Select the option Oracle Database 10g Companion Products 10.2.0.1.0 because only HTTP Server is needed :-
Select the Path depending on the space in the drives but the HTTP Server home should be separate from Oracle Database Home :-
Select the Apache Standalone option and click on Next :-
Save the Information about the HTTP server :-
Installation of Application Express :-
Checking the shared_pool_size of the Target Database :-
Enter the following command to determine whether the system uses an initialization parameter file (initsid.ora) or a server parameter file (spfiledbname.ora):-
Determine the current values of the shared_pool_size parameter :-
If the system is using a server parameter file, set the value of the SHARED_POOL_SIZE initialization parameter to at least 100 MB:-
If the system uses an initialization parameter file, change the values of the SHARED_POOL_SIZE parameter to at least 100 MB in the initialization parameter file (initsid.ora) :-
Before Installing Oracle Application Express, Oracle recommends that you complete the following steps :-
1. Shut down any existing Oracle Database instances as well as Oracle-related processes.
Shut down any existing Oracle Database instances with normal or immediate priority, except for the database where you plan to install the Oracle Application Express schemas. On Real Application Clusters (RAC) systems, shut down all instances on each node.
If Automatic Storage Management (ASM) is running, shut down all databases that use ASM except for the database where you will install Oracle Application Express, and then shut down the ASM instance.
Shut down any existing Oracle Database instances with normal or immediate priority, except for the database where you plan to install the Oracle Application Express schemas. On Real Application Clusters (RAC) systems, shut down all instances on each node.
If Automatic Storage Management (ASM) is running, shut down all databases that use ASM except for the database where you will install Oracle Application Express, and then shut down the ASM instance.
You can use the Windows Services utility, located either in the Windows Control Panel or from the Administrative Tools menu (under Start and then Programs), to shut down Oracle Database and ASM instances. Names of Oracle databases are preceded with OracleService. The Oracle ASM service is named OracleASMService+ASM. In addition, shut down the OracleCSService service, which ASM uses. Right-click the name of the service and from the menu, choose Stop.
2. Back up the Oracle Database installation.
Oracle recommends that you create a backup of the current installation of Oracle Database installation before you install Oracle Application Express. You can use Oracle Database Recovery Manager, which is included the Oracle Database installation, to perform the backup.
Oracle recommends that you create a backup of the current installation of Oracle Database installation before you install Oracle Application Express. You can use Oracle Database Recovery Manager, which is included the Oracle Database installation, to perform the backup.
3. Start the Oracle Database instance that contains the target database.
After backing up the system, you must start the Oracle instance that contains the target Oracle database. Do not start other processes such as the listener or Oracle HTTP Server. However, if you are performing a remote installation, make sure the database listener for the remote database has started. To start the database instance or listener, you can use the Windows Services utility.
To install Oracle Application Express release 3.0:
1. Download the file apex_3.0.zip from the Oracle Application Express download page. See:http://www.oracle.com/technology/products/database/application_express/download.html
2. Unzip apex_3.0.zip as follows, preserving directory names:
o UNIX and Linux: Unzip apex_3.0.zip
o Windows: Double click the file apex_3.0.zip in Windows Explorer
3. Change your working directory to apex.
Change the working directory where the apex folder exists and then connect to the database by SYS user :-
1. Run apexins.sql passing the following five arguments in the order shown:
@apexins password tablespace_apex tablespace_files tablespace_temp images
Where:
o password is the password for the Oracle Application Express administrator account, the Application Express schema owner, and the Application Express files schema owner.
The Application Express schema owner is the user or schema into which Oracle Application Express database objects will be installed. The Application Express files schema owner is the user or schema where uploaded files are maintained in Oracle Application Express.
o tablespace_apex is the name of the tablespace for the Oracle Application Express application user.
o tablespace_files is the name of the tablespace for the Oracle Application Express files user.
o tablespace_temp is the name of the temporary tablespace.
o images is the virtual directory for Oracle Application Express images. To support future Oracle Application Express upgrades, define the virtual image directory as /i/.
The following examples demonstrate running apexins.sql and passing these arguments:
@apexins password SYSAUX SYSAUX TEMP /i/
Copying the Images Directory :-
Copying the Images Directory in a New Installation :-
On Windows:
xcopy /E /I ORACLE_HOME\apex\images ORACLE_HTTPSERVER_HOME\Apache\images
Configuring Oracle HTTP Server 10g :-
Editing the dads.conf File :-
If this is a new installation of Application Express, you need to edit the dads.conf file. The dads.conf file contains the information about the DAD to access Oracle Application Express.
Use a text editor and open the dads.conf.
On Windows see: ORACLE_HTTPSERVER_HOME\Apache\modplsql\conf\dads.conf
In the dads.conf file, replace ORACLE_HTTPSERVER_HOME, host, port, service_name, and apex_public_user_password with values appropriate for your environment. Note that the apex_public_user_password is the password you defined when you installed Oracle Application Express.
Change mgr to manager :-


Stopping and Restarting Oracle HTTP Server :-
· ORACLE_HTTPSERVER_HOME\opmn\bin\opmnctl stopproc ias-component=HTTP_Server
· ORACLE_HTTPSERVER_HOME\opmn\bin\opmnctl startproc ias-component=HTTP_Server
Go to link http://odtemp-pc.idc.oracle.com:7777/pls/apex/apex_admin to access application express console :-
Installation of ILM :-
Download the ILM Assistant from :-
http://www.oracle.com/technology/software/deploy/ilm/index.html
Extract the ILM Assistant V1.3.exe into a new folder which is named as ILMA here.
Go to command prompt and change the directory to place where we have the ILMA folder :-

Connect to database through SYS user :-
Run the script :-
SQL> @ilma_install apex_password tablespace connect
Where :-
Apex_password is the password of application express schema owner (FLOWS_nnnnnnn).
Note :- apex_password is the initial password assigned to the following users created by this installation :-
The Oracle user ILM_TOOLKIT into which ILM Assistant database objects are installed.
The ADMIN user for application express workspace ILM_TOOLKIT.
Tablespace is the tablespace in which to store ILM Assistant database objects created by this installation.
Connect is the Oracle Net connect string to the database. If this is local install,use none or NONE.
For Example :- SQL> @ilma_install MY_APEX_PWD ILM_ASSISTANT none
After successfully executing the installation script,a required post installation script must be executed.The purpose of this script is to prepare any internal caching tables for use by ILM Assistant :-
SQL> @ilma_post_install
SQL> @ilma_post_install
Run ILM Assistant using a browser by navigating to a link :-
http://odtemp-pc.idc.oracle.com:7777/pls/apex/f?p=737677
http://odtemp-pc.idc.oracle.com:7777/pls/apex/f?p=737677
Subscribe to:
Comments (Atom)